
Графоаналитический метод
Принципы отбора лексического материала для иследований рассматриваются отдельно
В исследованиях доисторических этногенетических процессов использовался разработанный автором графоаналитический метод, и его эффективность была доказана полученными результатами, которые подтверждаются другими исследованиями. Метод является одновременно способом и средством познания взаимоотношений близкородственных языков на ранней стадии их развития, обусловленных особенностями природной среды. Он был впервые описан в 1987 р. в статье "Определение мест поселения древних славян графоаналитическим методом" в журнале "Известия Акадамии наук СССР. Серия литературы и языка". Фактически метод является практической реализацией теоретических рассуждений украинского филолога Иллариона Свенцицкого, который, отстаивая необходимость применения математики в гуманитарних науках, писал:
Важным является только то, что всякие взаимоотношения человеческие и вообще мировые легче всего обозначать числом, объемом и положением в пространстве и времени, благодаря чему они легко укладываются в рамки математических символов (Свєнціцкий І., 1927, 53)
Графо-аналитический метод (GAM), действительно, определяет относительное положение родственных языков в пространстве в определенное время, что позволяет исследовать происхождение и развитие языков в доисторический период. Идея метода состоит в геометрической интерпретации взаимосвязей родственных языков на основании количественной оценки общих языковых единиц в парах языков одной языковой семьи или группы. Большее родство языков обычно связывается с большим количеством общих языковых единиц, из которых для статистической обработки более всего подходят слова. Большое количество слов позволяет избежать чрезмерной значимости отдельных языковых единиц для оценки родства, когда их количество мало. Отправной точкой при разработке метода было предположение о существовании обратно пропорциональной зависимости между количеством общих слов (точнее лексем) в паре языков и расстоянием между ареалами, на которых эти языки сформировались. Проще говоря, чем ближе проживали друг к другу носители двух родственных языков, тем больше в их языках общих слов. Ясно, что имеются в виду слова древние, такие, которыми человек мог пользоваться еще в доисторические времена, а не те слова, которые возникли позже на более высоких ступенях общественного развития. Выделить слова древнего происхождения непросто, но реально, для этого имеются есть разные методы.
Метод позволяет построить графическую модель родственных отношений языков одной семьи или группы, для которой имеется только одно соответствие на поверхности Земли. Метод базируется на использовании одного из видов графов, который, возможно, еще ждет своего описания в математике (автор, по крайней, мере в теории графов его не обнаружил). Пока что он может быть охарактеризован как “взвешенный” граф, в котором связи существуют не между отдельными узлами, а обязательно между ними всеми, причем важной является не только сама связь, но и ее интенсивность, отражаемая расстоянием между каждым из узлов. В нашем случае длина ребра графа соответствует числу общих слов в паре языков. Однако точное число таких слов нам неизвестно, поскольку в словарях обнаружить их все невозможно. Для построения графа нужно найти близкие к реальности координаты узлов на основе неточных данных о длине ребер, которые их соединяют. В принципе построение графа возможно, если длина ребер не очень искажена, но узлы уже будут выглядеть не отдельными точками, а множеством компактных точек. Чем компактнее будут расположены точки в пределах множества и чем далее одно от другого расположены эти множества, тем точнее построен граф.
Говоря о «общих словах» при изучении родства языков, мы имеем в виду слова, принадлежащие к определенному этимологическому комплексу, которые имеют как фонетическое, так и семантическое сходство.
Для удобства подсчета общих слов использовались два типа словарей. Вначале составлялся семантический словарь, в котором набор заглавных слов помещался в столбец и для каждой сематической единицы приводились соответствия из анализируемых языков. Затем полученные синонимические гнезда были проанализированы на фонетическое сходство, что позволило выделить из них этимологические комплексы, в который входили слова в определенной мере подобные. Второй тип представлял собой матрицу, в одном из вертикальных столбцов которой имелся набор идентификаторов для найденных этимологических комплексов. Соответствия для них размещались в горизонтальных строках, также образующих столбцы для каждого из языков. Когда совпадения присутствовали на всех или почти на всех языках, этот этимологический комплекс исключался из расчетов, поскольку он являлся общей единицей прародительского языка мог квозникнуть в другом месте и в другое время. Разработанный таким способом этимологические словари-таблицы для разных языковых семейств и групп обеспечили легкий подсчет количества общих слов в языковых парах, необходимые для построения графов или, другими словами, графических моделей языковых отношений внутри языковых семейств или групп. Когда количество взаимных слов в языковых парах подсчитано, можно определить набор ребер, необходимых для построения графической модели.
Графоаналитический метод был использован для исследования родственных связей ностратическоих, индоевропейских, финно-угорских, тюркских, иранских, германских, славянских, сино-тибетских, монгольских и тунгусо-маньчжурских языков. Лексический матераил для заполнения этимологических таблиц-словарей языков входящих в ностратическую макросемью основном брался из имеющихя этимологических словарей [Абаев В.И. 1958-1989; Алатырев В.И. 1988; Георгиев В.Л., Гълъбов Ив. 1971; Егоров В.Г. 1964; Корнилов Г.Е. 1973; Лыткин В.И., Гуляев Е.С., 1970; Фасмер М. 1964-1973; Мартынаў В.В. 1978; Мельничук О.С. (Ред.) 1982-2006; Наджип Э.Н. 1979; Расторгуева В.С., Эдельман Д.И. 2003; Севортян Э. В. 1974; Трубачев О.Н. (Ред.) 1974.; Эдельман Д.И. 2001; Acharrjan Hr. 1971. Bezlaj France. 1976; Boisaq E. 1923; Brükner Aleksander. 1957; Clauson Gerard, Sir, 1972; Fraenkel E. 1955-1965; Frisk H. 1970; Häkkinen Kaisa. 2007; Holthausen F. 1934; Holthausen F. 1974; Hübschmann Heinrich. 1972; Kluge Friedrich, Seebold Elmar. 1989; Kopečny František. 1981.; Machek V. 1957; Meyer-Lübke W. 1992; Morgenstierne Georg Valentin. 1927.; Pokorny J. 1949-1959; Schuster-Schewc H. 1976; Sławski F. 1974; Tóth Alfrėd. 2007; Veen P.A.F. van, Sijs Nicoline van der. 1997; Walde Alois, Hofmann J.B., Berger Elsbeth. 1965.; Zaicz Gábor. 2006]. Однако в этимологических словарях очень часто приводятся далеко не все соответствия заглавному слову. Поэтому дополнительный материал брался их множества других словарей, как двуяычных, так и тематических. При работе со словарями разных языковых семейств необязательно иметь хорошее владение всеми этими языками, но необходимо знать их фонологические особенности в соответствии с требованиями сравнительно-исторического языкознания [Мейе А. 1938; Мейе Антуан. 1954; Фортунатов Ф.Ф. 1956; Гамкрелидзе Т.М., Иванов В.В. 1984]. Работа Х.Краэ [Krahe Hans, 1966] использовалась при подборе и систематизации слов индоевропейских языков. Фонетические правила финно-угорских языков взяты из книги российских лингвистов Лыткина и Гуляева [Лыткин М.И., Гуляев Е.С. 1970] и фонетические закономерности тюркских языков были взяты из классификации Баскакова [Баскаков Н.А. 1960]. Для построения моделей родства сино-тибетских, монгольских и тунгусо-манчжурских языков использовалась база данных Вавилонская башня. Составленные для расчетов Етимологические словари-таблицы постоянно исправляются и пополняются, что позволяет строить все более совершенные графические модели родства языков.
Графоаналитический метод может найти применение не только в языкознании, но и в других науках, где проявляется корреляция между большим количеством общих признаков разных объектов и расстоянием между объектами в пространстве (необязательно даже в двухмерном). Этот метод был проверен, например, на статистических данных Федорова-Давыдова (Федоров-Давыдов Г. А., 1987) о количестве общих признаков орнаментальных композиций среднеазиатской керамики, произведенной несколькими мастерами, жившими в разных частях Пенджикента. Поскольку художественные взаимовлияния мастеров были тем сильнее, чем ближе они между собой проживали, то стало возможным определить расположение их мастерских на территории города. Конечно, проверить эти данные невозможно, поскольку неизвестно, где в действительности жили мастера, но сама возможность построения уже является определенным свидетельством действенности метода.
Нужно особенно подчеркнуть, что графоаналитический метод эффективен только при обработке абсолютных величин или отнесенных к одной общей. Отнесение количества общих признаков между двумя объектами к их общему количеству в этих языках или в одном из них не может достаточно характеризовать эти два объекты, поскольку общее количество признаков какого-либо из объектов само зависит от расположения объекта среди других. Маргинальные объекты имеют меньшее общее количество признаков, характерных для этой ассоциации, и это уже характеризует их периферийное положение. Когда же мы возьмем это сниженное значение в знаменателе, оно нам искусственно увеличит соотношение. Это не означает, что маргинальные объекты вообще имеют меньшее признаков. Они их могут иметь даже и больше, но их часть может уже быть общей не с объектами исследуемой ассоциации, а соседней.
Процесс построения схем родства графоаналитическим методов по лексико-статистическим данными показан на конкретном примере ностратических языков по данным результатов исследований В. М. Иллича-Свитыча (Иллич-Свитыч В. М., 1971). Сам факт построения схемы родства языков ностратических языков будет свидетельствовать об этом. В. М. Иллич-Свитыч исследовал лексические, словообразовательные и морфологические сходства шести больших языковых семей Старого Света: алтайской, уральской, дравидийской, индоевропейской, картвельской и семито-хамитской. Часть данных, полученных в результате исследований Иллича-Свитыча, была представлена в таблицах (морфологические признаки и лексика в количестве 147 позиций), а еще 286 лексических параллелей можно было найти в тексте его книги, к которым при проверке всего материала с данными Андреева было дополнительно добавлено 27 слов из уральских и 8 из алтайских языков (Андреев Н. Д., 1986). Тут необходимо заметить, в составе всего материала алтайских языков настолько преобладают примеры из языков тюркских, что фактически именно о них и должна была бы идти речь, однако мы пока оставляем термин «алтайские языки» в понимании Иллича Свитыча.
После обработки всех материалов Иллича-Свитыча и Андреева оказалось, что из 433 всего количества признаков 34 являются общими (к ним мы еще вернемся), а остальное соответствовали 255 единицам из уральских, также 255 единицам – из алтайских, 253 единицам из индоевропейских, 240 – из семито-хамитских, 189 – из дравидийских и 139 из картвельских. Затем было подсчитано количество общих признаков в парах языков, но при этом не учитывалось разная весомость морфологических признаков и лексических единиц, хотя это совсем разные категории. Однако количественная оценка этой весомости все равно была бы субъективной, поэтому будем надеяться, что морфологические признаки распределились среди языков более или менее равномерно. Подсчеты дали результаты, представленные в таблице 1:
Таблица 1. Количество общих признаков между семьями языков
| алтайские – уральские | 167 | уральские – картвельские | 66 |
| алтайские – индоевропейские | 153 | индоевропейские – семито-хамитские | 147 |
| алтайские – семито-хамитские | 149 | индоевропейские – дравидийские | 108 |
| алтайские – дравидийские | 109 | индоевропейские – картвельские | 70 |
| алтайские – картвельские | 84 | семито-хамитские – дравидийские | 110 |
| уральские – индоевропейские | 151 | семито-хамитские – картвельские | 86 |
| уральские – семито-хамитские | 136 | дравидийские – картвельские | 54 |
| уральские – дравидийские | 134 |
Проанализировав полученные данные, нельзя сразу найти в них какую-либо закономерность, однако можно заметить, что больше всего общих слов имеют между собой алтайские, уральские, семито-хамитские и индоевропейские. Эти языки определяют характер конфигурации будущего графа. Сначала нужно выбрать коэффициент пропорциональности, а далее пересчитать количества общих признаков в расстояния между ареалами языков. Выбор значения коэффициента определяется размерами листа, на котором строится схема. В соответствии с нашими данными подходит значение K=1000. Тогда расстояния между ареалами отдельных языков будут иметь значения, представленные в таблице 2:
Таблица 2. Расстояния между центрами языковых семей на схеме, см.
| алтайские – уральские | 6.0 | уральские – картвельские | 15.2 |
| алтайские – индоевропейские | 6.5 | индоевропейские – семито-хамитские | 6.8 |
| алтайские – семито-хамитские | 6.7 | индоевропейские – дравидийские | 9.3 |
| алтайские – дравидийские | 9.2 | индоевропейские– картвельские | 14.3 |
| алтайские – картвельские | 11.9 | семито-хамитские – дравидийские | 9.1 |
| уральские – индоевропейские | 6.6 | семито-хамитские – картвельские | 11.6 |
| уральские – семито-хамитские | 7.4 | дравидийские – картвельские | 18.5 |
| уральские – дравидийские | 7.5 |
Построение схемы родства идет несколькими итерациями. Сначала по двум координатам для каждого языка находится одна точка, которая определяет приблизительное положение ее ареала, а в следующих итерациях идет уточнение расположения всех ареалов языков. В принципе можно начать с любого языка, но сразу неизвестно, в какую сторону пойдет построение, и схема может выйти за пределы листа. Поэтому удобнее всего начать построение с пары языков, которые имеют наибольшее количество общих признаков. В нашем случае это алтайские и уральские языки. Следовательно, сначала произвольно расположим где-то в центре листа отрезок AB длиной 6 см, который соответствует количеству общих признаков в этой паре (см. Рис. 5). Концы этого отрезка определяют место точек для алтайских и уральских языков. Далее на базе этого отрезка строятся точки для индоевропейских и семито-хамитских языков. Начнем с семито-хамитских, поскольку эти языка имеют больше общих признаков с картвельским и дравидийскими, чем индоевропейские. В соответствии с количеством общих признаков точка семито-хамитских языков должна находиться на расстоянии 6,7 см от точки алтайских и на расстоянии 7,4 см от точки уральских языков. Циркулем с соответствующим раствором делаем две засечки и на их пересечении находим точку семито-хамитских языков. Таких точек может быть две – слева и справа от базы. Выбор одной из этих двух возможных точек определяет окончательный вид схемы, которая может иметь два варианте, зеркальные по отношению друг к другу.
Выберем точку, которая лежит ближе к центру. Теперь у нас три точки – A, B, C, и мы переходим к построению точки D (индоевропейские языки). Ее положение определим тоже на базе отрезка AB. Она должна быть на расстоянии 6,5 см от точки A и на расстоянии 6,6 см от точки B. Циркулем делаем две соответствующие засечки в сторону, противоположную от точки C и получаем точку D. (Располагать ее возле точки C нельзя, поскольку в этом случае семито-хамитские и индоевропейские языки должны были бы иметь значительно больше общих признаков, чем они имеют на самом деле). Точку E для дравидийских языков строим на базе BC, поскольку именно семито-хамитские и уральские языки имеют более всего общих признаков с дравидийскими. Итак, эта точка располагается на расстоянии 7,5 см от точки уральских языков и на расстоянии 9,1 см от точки семито-хамитских языков в направлении от центра схемы, иначе она ляжет возле точки алтайских языков, почему противоречит количество общих признаков между ними. Аналогично строится точка F для картвельских языков, только в этом случае на базе AC. После этого первая итерация закончена – получена скелетная схема родства ностратических языков. Их ареалы должны быть где-то в районе полученных точек A, B, C, D, E, F.
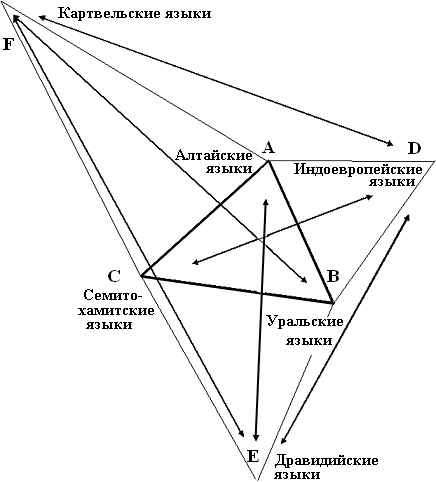
Рис. 5. Первая итерация построения схемы родства ностратических языков
Вторая итерация дает возможность уточнить и проверить правильность расположения ареалов. Теоретически точки отдельных языков можно построить по другим координатам. Например, точка D строилась по двум координатам, которыми были отрезки AD и BD при отрезке AB в качестве базы для них. Теперь мы можем использовать в качестве координат, скажем, те же самые отрезки в других сочетаниях – с отрезками, которые отвечают расстоянию между индоевропейским и ареалами дравидийских, семито-хамитских и картвельских языков.
При этом мы должны выбирать в качестве базы отрезок смежный тем, которые испльзуются в качестве координат. Практически это невозможно осуществить, потому что положение иной базы до окончения построения графа остается все-таки неопределеннм. Однако вторую итерацию можно провести проще. На рисунке 5 уже хорошо видно, что центры ареалов индоевропейского и семито-хамитских языков в соответствии с количеством общих слов должны были бы быть ближе один к другому. По той же причине центр ареала картвельских языков должен быть ближе к индоевропейским, а центр ареала дравидийских – ближе к семито-хамитским, алтайским и индоевропейским. Приблизив соответственно точки C и D, F и D, E и C, E и B, и отложив на прямой, содиняющей эти точки, отрезок, отвечаюший количеству общих слов в соответствующих языках, мы получим граф, показанный на рисунке 6.
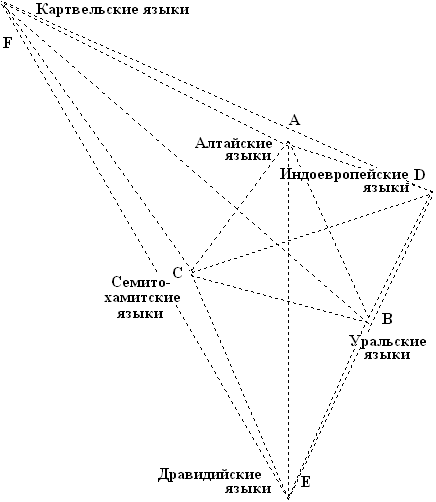
Рис. 6. Вторая итерация построения схемы
родства ностратических языков
Теперь концы отрезков будут расположены более компактно. Можно провести еще третью итерацию таким же образом, если видно, что условные центры ареалов нужно передвинуть снова. Окончательно схема, или уже графическая модель семейных отношений ностратических языков, принимает вид, показаний на рисунке 7. Она обладает определенными фрактальными свойствами, частности, напоминает треугольник Серпинского. Модель является одним из двух зеркальных вариантов, из которых выбрано именно этот по той причине, что именно для него удалось найти место на географической карте. Здесь нужно только обратить внимание, что при поисках соответствующего места на географической карте для получаемых схем родства нужно каждый раз подбирать новый коэффициент пропорциональности в соответствии с масштабом карты, то есть строить геометрически подобную схему другого размера в соответствии с размерами ареалов на карте.
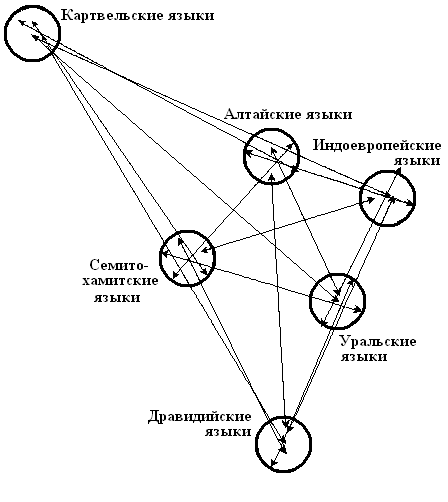
Рис. 7. Схема родственных отношений ностратических языков
Построение графической модели родства по лексико-статистическим данным вполне может быть автоматизированным. Для этого нужно составить программу для компьютера. Это задача для прикладной математики, в которой составление математических моделей систем является обычным делом. Автоматические построенные модели вызывали бы большее доверие, но взяться за такую работу пока никто из знакомых мне прикладных математиков не решился. Очевидно, это все-таки не простая задача.
Применение графоаналитического метода привело в конечном итоге к открытию феномена энтоформирующих ареалов. Их существование является своего рода эмпирическим обобщением, которое, по выражению Вернадского, "не отличается от научно установленного факта" (Вернадский В.И. 2004, § 15).
Количественные данные о лексике исследованной при помощи графоаналитического метода в течение сорока лет.
| Семьи и группы языков | Количество языков | Количество этимологических комплексов | Общее количество слов |
| Сино-тибетская | 7 | 2.775 | 9.700 |
| Тунгусо-маньчжурская | 11 | 2.234 | 10.200 |
| Монгольская | 8 | 2.250 | 8.500 |
| Ностратическая | 6 | 433 | 2.600 |
| Абхазо-адыгская | 5 | 1.800 | 4.500 |
| Нахско-дагестанская | 27 | 1.900 | 24.000 |
| Индоевропейская | 14 | 2.554 | 12.381 |
| Финно-угорская | 12 | 1.913 | 9.584 |
| Тюркская | 13 | 2.558 | 19.670 |
| Германская | 6 | 2.630 | 11.065 |
| Иранская | 11 | 1.773 | 8.249 |
| Славянская | 10 | 3.200 | 12.000 |
| Всего | 130 | ≈ 26.000 | ≈ 135.000 |

![]()