
Основні постулати.
Опис етногенетичних процесів в Східній Європі буде базуватися на результатах проведених досліджень як спорідненості мов, належних до однієї сім’ї або групи, так і спорідненості самих мовних груп і сімей. Більша спорідненість мов звичайно пов’язується з більшою кількістю тотожних за походженням слів, і така концепція сформувалася у мовознавців ще в минулому столітті (Фортунатов Ф.Ф., 1956, 68-69). Відповідно до цієї концепції в даних дослідженнях використовувався так званий графоаналітичний метод, в основі якого лежить кількісна оцінка та геометрична інтерпретація спільних лексичних одиниць мов різного ступеню спорідненості. Короткий опис методу був даний раніше (Стецюк В.М., 1987, 36-37), але в журнальній статті не було можливості пояснити його певні особливості, без пояснення яких цей метод неодмінно буде викликати заперечення спеціалістів, котрі мають свої власні погляди щодо принципових питань історії мов. Перше ніж перейти до опису методу, подамо основні постулати, з яких будемо виходити при використанні методу, та ті наслідки, які з них випливають. Ці постулати я встановив довільно як припущення при рішенні поставленого перед собою конкретного завдання.
Постулат перший – Мовний континуум
Умоглядно та на підставі спостережень дослідників за мовою первісних народів припускається, що при розселенні якогось етносу – носія певної мови на достатньо великій рівнинній території без особливих географічних перешкод, котрі б утруднювали спілкування окремих груп цього етносу між собою, в процесі культурного розвитку даного етносу і пов’язаного з ним збільшення словникового складу його мови з часом з цієї мови розвиваються окремі споріднені між собою діалекти в числі залежному від площі території, які утворять такий мовний континуум, при котрому різниця між окремими діалектами буде зростати монотонно пропорційно відстані, на котрій мешкають окремі групи первісного етносу – носії цих діалектів, при допущенні їх більш-менш осілого способу життя. Іншими словами висловив цей постулат більше ніж 100 років тому Г.Пауль в своїй роботі "Принципи історії мови" :
Ми повинні визнати, що на світі стільки ж мов, скільки індивідів…Якщо б інтенсивність спілкування була рівномірною в усіх точках даної мовної території, то індивідуальні мови там, де вони тісно між собою пов’язані, породжували би тільки незначні відхилення, в той час як на протилежних кінцях території все ще б виникали різкі розходження. Тоді б не можна було виділити яку-небудь групу індивідуальних мов, щоб протиставити її як замкнену цілісність іншій такій самій групі. Мову кожного індивіду можна було б розглядати як перехідний ступінь до мов інших індивідів. Такого становища, однак, ніде не існувало. Воно стало б можливим, якби не було природних границь, ні політичних і релігійних об’єднань, якби, скажімо, весь народ мешкав на єдиній рівнині, не пересіченій якоюсь значною рікою, на відокремлених хуторах, розташованих на однаковій відстані один від одного, без загальних місць збору. Втім, і в цьому випадку спостерігався б процес об’єднання мов – хоча б в мови окремих сімейств (Пауль Г., 1960, 58, 61).
Пауль був одним з представників младограматичної школи, теоретичні основи якої тепер вже не залишилися непорушними, але в даному випадку він мав рацію, хоча помилявся в тому, що описаного ним становища ніде не існувало. Майже ідеальні умови для розвитку мови згідно описаного ним сценарію існували в рівнинній Австралії, не пересіченій якимись значними ріками. Ось як тамтешню мовну ситуацію описує В.А.Шнірельман :
Для аборигенів Австралії характерна лінгвістична безперервність, тобто мови або діалекти сусідніх груп відзначалися більшою подібністю, а їх носії добре розуміли один одного, тоді як з віддаленням груп одна від одної взаєморозуміння поступово зникало (Шнирельман В.А., 1982, 88).
Слід мати на увазі, що розходження між діалектами в Австралії були чисто лексичні, бо "єдиний фонетичний ареал охоплював майже всю територію Австралії" (Шнирельман В.А., 1982, 89).
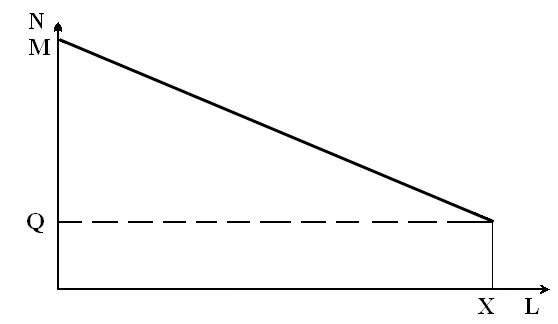
Мал. 1. Розподіл кількості спільних слів між діалектами на території без географічних границь.
N – кількість спільних слів між діалектами. L – відстань між ареалами поселень. M – загальна кількість слів в одному з діалектів. Q – кількість слів першого рівня для всіх діалектів. Х – відстань, на якій зникає спільність новоутворених слів.
Постулат другий – Хронологічне розшарування словникового складу
Якщо первісний етнос на початку розселення на будь-якій території мав мову з множиною лексичних одиниць Q, то утворення континууму нових діалектів проходить двома шляхами, – по-перше, утворенням і поширенням між діалектами нових слів і загальним збільшенням кількості лексичних одиниць в мові, а, по-друге, зменшенням в кожному діалекті первісної множини Q. Однак обидва процеси мають різну швидкість – процес утворення і поширення нових слів іде із швидкістю на порядок вищою, ніж процес зникнення слів первісної множини, в результаті чого в кожному з діалектів, завжди можна розшарувати весь словниковий склад на дві верстви – слова, успадковані від прамови, котрі назвемо словами першого рівня, і нові слова, котрі назвемо словами другого рівня. Правда, не всі слова першого рівня є спільними для усіх діалектів. Бувають випадки, коли раніше спільні слова зберігаються лише в маргінальних ареалах, в той час як в мовах центральних ареалів, які перебувають і тісних контактах між собою, ці слова можуть замінятися новими формами і значеннями. В такому випадку слова, які збереглися у маргінальних мовах, теж відносяться до слів другого рівня.
Треба тільки зробити уточнення, що на постульовану вище залежність кількості спільних слів від відстані між діалектами фактично будуть впливати тільки слова другого рівня, бо слова першого рівня будуть залишатися в усіх діалектах в приблизно однаковій кількості. Якщо відобразити описану мовну ситуацію на нашій гіпотетичній території типу Австралії графічно, то вона буде мати вигляд, поданий на малюнку 1.
Оскільки співвідношення між діалектами інваріантне, тобто кількість спільних слів другого рівня у них залежить тільки від відстані між ними і не залежить від їх розташування відносно інших діалектів, залежність між кількістю спільних слів другого рівня в діалектах і відстанню між поселеннями їх носіїв буде лінійною і виражатиметься функцією
N = (M – Q) – kL,
де k – коефіцієнт пропорційності, котрий залежить від густини населення, кількості діалектних угруповань та інших факторів.
Постулат третій – Існує обернено пропорційна залежність між кількістю спільних рис у парі мов і відстанню між ареалами, на яких сформувалися ці мови.
Якщо територія поселення етносу – носія певної мови має географічні перепони, які перешкоджають рівномірному пересуванню і спілкуванню окремих його груп і спричиняють утворення більш-менш сталих ареалів поселень цих груп, то на даній території виникає не континуум діалектів, а певна кількість дискретних діалектів в межах ареалів, границями між якими є ці географічні перешкоди. Своєрідність географічної особливості таких ареалів призводить до того, що відокремлення первинних етнічних осередків на них може відбуватися неодноразово, тому їх можна називати етноформуючими ареалами. Розмір таких ареалів, на яких виникають лінгвістичні і культурні новації, не може бути занадто великим, інакше в їх може виникнути мовний континуум, що не сприятиме консолідації населення в єдину етнічну одиницю.
Наслідком існування природних міжетнічних границь є те, що мовний континуум на території поселення порушується, і функція N = (M – Q) – kL в пункті перетину цієї границі терпить розрив. Простіше кажучи, кількість спільних мовних ознак (у тому числі, слів) між окремими групами населення в межах ареалу зменшується монотонно пропорційно відстані між їх поселеннями (але з меншою швидкістю ніж на території типу Австралії, бо в межах ареалу населення має тепер тісніші контакти), а на кордоні ця кількість спільних ознак зменшується стрибкоподібно. Можна припустити, що при кожному перетині кордону втрачається певний більш-менш сталий процент спільних слів другого рівня. В такому випадку розподіл кількості спільних слів залежно від відстані буде мати вигляд, показаний на малюнку 2 ламаною лінією MTUVWXYZ. Зменшений темп лексичних змін в межах ареалу відбивається на малюнку 2 прямою MS, яка є тепер менш похилою, ніж на малюнку 1.
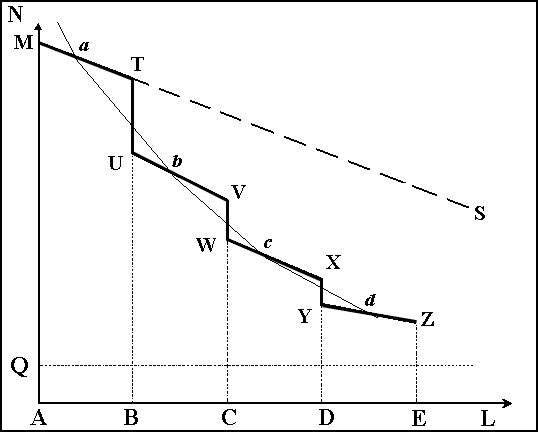
Мал. 2. Розподіл кількості спільних слів між діалектами на території, розділеній етнічними кордонами.
N – кількість спільних слів між діалектами. L – відстань між ареалами поселень. Q – кількість слів першого рівня для всіх діалектів. M – загальна кількість слів в одному з діалектів. AB, BC, CD, DE, – області окремих діалектів
Математично отриманий розподіл у вигляді ломаної лінії виражається досить складно. Однак, прийнявши новоутворені діалекти в межах ареалів AB, BC, CD, DE за окремі мовні одиниці, ми можемо вважати відстань між ними рівною відстані між їх центрами. Тоді, з’єднавши центри відрізків MT, UV, WX, YZ, ми отримаємо розподілення спільних слів між діалектами у вигляді лінії abcd. Якщо перенести початок координат в точку Q, то можна побачити, що ця лінія за своєю формою у середній частині наближена до гіперболи і тому досить точно може бути описана обернено пропорційною функцією y=k/x. Тоді в нашому випадку залежність між кількістю слів другого рівня в діалектах і відстанню між центрами поселень їх носіїв буде приблизно виражатися формулою:
M – Q = K/L
Певна замкненість етноформуючих ареалів кінець-кінцем обумовить значне зростання різниці між елементами мов їх населення і ця різниця приведе до формування нових мов, котрі ми далі будемо називати мовами другого рівня. При переселенні етносу – носія мови другого рівня на нову велику територію ця мова може знову розчленуватися і утворити нові мови третього рівня, в котрих залишаться множини слів першого і другого рівня. Цей процес з часом може продовжуватися далі так, що через певний час можуть виникати мови третього, четвертого і навіть п’ятого рівнів, утворюючи так зване "родовідне дерево". У певному сенсі він є подібним процесу формування фрактальної множини геометричних фігур.
Наслідком цього є те, що в мовах найвищого рівня будуть зберігатись множини слів усіх нижчих рівнів, але тільки слова найвищого рівня будуть підпорядковані закону оберненої пропорційності, коли кількість спільних слів цього рівня у парах мов буде залежати від відстані між ареалами, на яких формувалися ці мови.
Отже, коли ми будемо досліджувати мови вищого рівня, ми повинні вилучати з досліджуваного лексичного матеріалу всі слова нижчих рівнів, котрі звичайно бувають спільними для всіх досліджуваних мов, і це значно полегшує їх вилучення.
Множина всіх мов, які походять від єдиної мови-предка, утворює рід мов, котрі будуть споріднені між собою на різних рівнях. Отже, якщо ностратичні мови виникли від одної прамови, яка в даному випадку є мовою першого рівня, то тоді праіндоєвропейська, праалтайська, прауральська, прасеміто-хамітська, пракартвельська та прадравідійська мови є мовами другого рівня, які споріднені між собою на першому рівні. Далі, наприклад, прагерманська, праслов’янська, давньогрецька та інші індоєвропейські мови є мовами третього рівня, які споріднені між собою на другому рівні. Слов’янські мови українська, польська, білоруська та інші є мовами четвертого рівня і споріднені між собою на третьому рівні. Діалекти української мови є умовно мовами п’ятого порядку, котрі споріднені між собою на четвертому рівні. Можна вважати спорідненими навіть і, наприклад, німецьку та марійську мови, але це буде спорідненість тільки на першому рівні.
Слід наголосити, що ідея мовного континууму, через який хвилями проходять мовні новотвори, які гальмуються будь-якими границями – природними, племінними, належить німецькому мовознавцю Шмідту. Він же перший зауважив, що географічно ближче розташовані мови мають більше спільного, ніж ті, котрі розташовані далі одна від одної (Trautman Reinhold, 1948, 18). Звичайно, що ця теорія хвиль Шмідта передбачала нерухомість і певну мовну консервативність населення і не враховувала можливих міграцій його окремих груп, колонізованих анклавів, військових вторгнень, але все-таки можна вважати, що в давні часи більша частина населення досить довго залишалася нерухомою, і ця відносна стабільність вела до певних закономірностей у формуванні діалектів, в той час як хаотичні взаємопроникнення окремих груп населення вели до безсистемних, випадкових впливів, котрі просто врівноважували один одного.
Постулат четвертий – Графічну схему взаємного розташування спорідених мов одного рівня, яка відбиває розташування ареалів поселень їх носіїв, можна побудувати на основі наявних лексичних даних.
Припустимо, що ми маємо географічну карту території, на якій сталося розчленування мови нижчого рівня на мови більш високого рівня A, B, C, D, E, F, з виразними етноформуючими ареалами, відстані між центрами котрих можна виміряти (див. малюнок 3).
На нашій карті ці відстані дорівнюють – AB – 3,9 см, AC – 4,9 см, AD – 8,0 см, AE = 9,3 см, AF – 10,6 см, BC – 2,9 см, BD – 4,2 см, BE – 5,6 см, BF – 7,4 см, CD – 4,2 см, CE – 7,4 см, CF – 5,8 см, DE – 4,0 см, DF – 3,8 см, EF – 7,5 см.
Припустимо також, що ми маємо можливість скласти повні словники кожної із новоутворених мов вищого рівня. Тоді, вилучивши із списків слова нижчих рівнів (спільні для всіх цих мов), ми можемо порахувати кількість спільних слів вищого рівня в кожній з можливих пар цих споріднених мов. Для зручності підрахунків можна скласти таку таблицю-словник, в котрій ми в крайній лівій вертикальній колонці розміщаємо повний список всіх лексичних ізоглос, котрі є наявні хоча б в одній з пар мов. В подальших вертикальних колонках, кожна з яких призначена для окремої мови, ми розміщаємо слова з наших словників таким чином, щоб в горизонтальних рядках розмістилися слова, спільні для двох, трьох і більше мов. Після цього за даними таблиці ми можемо легко підрахувати кількість спільних слів у парах мов. Якщо закон обернено пропорційної залежності кількості спільних слів у парах мов від відстаней між центрами ареалів поселень носіїв цих мов дійсно існує (тобто залежність M-Q = K/L є слушною), маючи в руках карту і знаючи відстані між центрами ареалів, ми можемо вирахувати значення коефіцієнту K в наведеній формулі, котре для кожної з пар мов має бути однаковим. Зрозуміло, що збіг не може бути дуже точним, оскільки теоретична обернено-пропорційна залежність відстані між центрами ареалів і кількістю спільних слів у парах мов не є абсолютною навіть і для однорідного простору, але реально простір не є однорідним, і слова поширюються по території з не зовсім однаковою швидкістю через різну проникність границь, різну їх довжину між ареалами та особливості конфігурації ареалів. Тому в нашій гіпотетичній ситуації значення коефіцієнту пропорційності не може бути абсолютно тотожнім для кожної з пар мов, а залишається в певних, хоча і вузьких межах, але для теоретичних обчислень воно має бути фіксованим для обраної групи мов відповідно до масштабу карти. В нашому прикладі ми насправді спочатку обрали значення K = 1000, а вже тоді, знаючи відстані між центрами ареалів на карті (малюнок 3), підрахували за формулою кількість спільних слів в парах мов, і ці дані мали би збігатися з тими підрахунками, котрі би ми могли зробити за допомогою описаної вище таблиці.
Пара мов AB – 256 спільних слів, AC – 204, AD – 125, AE = 108, AF – 94, BC – 345, BD – 238, BE – 179, BF – 135, CD – 239, CE – 136, CF – 172, DE – 250, DF – 263, EF – 134 спільних слова.
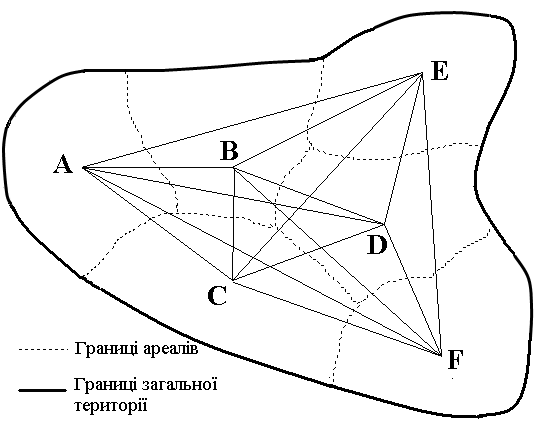
Мал. 3. Загальна територія поселення і окремі ареали поширення окремих мов
A, B, C, D, E, F – центри ареалів окремих мов
Припустимо тепер, що в силу випадкових факторів, частина даних з нашої таблиці-словника безслідно зникла, а з другого боку, в нього потрапили нові зовсім випадкові слова, що зіпсувало нам віддзеркалення родинних взаємин цих мов. Будемо вважати, зміни торкнулися кожної з мов більш-менш рівномірно, але в цілому словниковий склад змінився істотно.
Прийнявши можливі відносні похибки (ВП) в межах від 15 до 100%, змінимо в цих межах кількість спільних слів в кожній з пар мов і спробуємо за цими спотвореними даними відновити відому нам схему родинних взаємин цих мов. Наприклад, ми прийняли такі нові дані :
Пара мов AB – 333 спільних слів (ВП 23%), AC – 139 (ВП 47%), AD – 169 (ВП 26%), AE = 83 (ВП 30%), AF – 70 (ВП 34%), BC – 170 (ВП 103%), BD – 137 (ВП 74%), BE – 116 (ВП 54%), BF – 159 (ВП 15%), CD – 141 (ВП 70%), CE – 172 (ВП 21%), CF – 122 (ВП 41%), DE – 156 (ВП 60%), DF – 188 (ВП 40%), EF – 182 (ВП 26%) спільних слів.
Взявши той самий коефіціент пропорційності K = 1000, отримаємо нові дані для відстаней між центрами ареалів :
AB – 3,0 см, AC – 7,2 см, AD – 5,9 см, AE – 12,0 см, AF – 14,2 см, BC – 5,9 см, BD – 7,3 см, BE – 8,6 см, BF – 6,3 см, CD – 7,1 см, CE – 5,8 см, CF – 8,2 см, DE – 6,4 см, DF – 5,3 см, EF – 5,5 см.
Тепер накладем отримані відтинки на карту і тоди отримаємо картину, показану на малюнку 4.
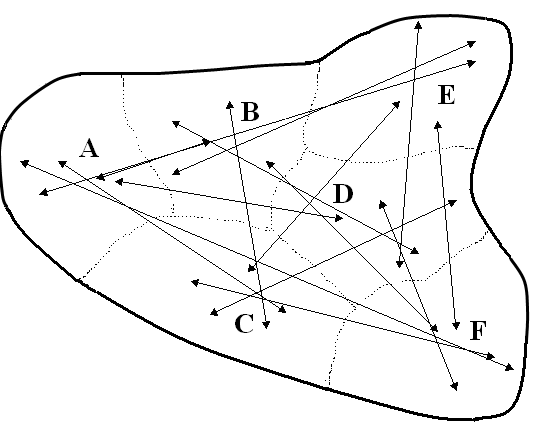
Мал. 4. Відтворена схема взаємин споріднених мов
На карті ми бачимо, що навіть спотворені дані дають нам можливість настільки точно віддзеркалити істинну схему родинних взаємин споріднених мов та розташування їх ареалів на карті, що для кожної мови залишається впевнено ідентифікованим той же самий ареал, що і на попередньому рисунку, бо кінці відтинків, не дивлячись на їх істотно змінену величину, розташовані досить компактно довкола центрів ареалів.
Середньо-арифметична відносних похибок Q = (23 + 47 + 26 + 30 + 34 + 103 + 73 + 54 + 15 + 70 + 21 + 41 + 60 + 40 + 26) : 15 = 44,3%. Отже, дані спотворені в дуже значним ступеню. Звідси випливає, що важливою є не стільки точність даних, скільки їх внутрішня структура, певна їх закономірність, і цю закономірність порушити нелегко.
Таким чином, можна бути певним, що якщо зміни словникового складу мов не досягли певної критичної межі, то ми зможемо на основі спотворених і неповних даних відновити істинну модель давніх взаємин і розташування споріднених мов настільки точно, що її можна буде пов’язати з певними географічними ареалами. Реально описаній вище штучно спотвореній таблиці може відповідати подібна таблиця-словник, котру можна скласти на підставі наявного в сучасних словниках лексичного матеріалу з використанням методів історично-порівняльного мовознавства, і ця таблиця буде віддзеркалювати давні взаємини мов і допоможе нам, як показав наведений вище приклад, побудувати просторову схему-модель взаємного розташування споріднених мов. Критерієм успіху є сама модель, бо вона може мати тільки один варіант, і якщо зібрані дані вкладаються в певну систему, то ця система не є випадковою, адже підібрати достатній лексичний матеріал для побудови вигаданої заздалегідь схеми неможливо. Якщо би хтось поставив собі за мету фальсифікувати наявні дані, то кількість слів у його вибірках не могли би перевершити і кількох десятків. Ми ж будемо намагатися оперувати із сотнями і тисячами слів.
Узагальнено можна сказати, що реально доводиться працювати з нечіткою множиною елементів, кожен з яких тільки певною мірою належить певній уявній множині, яка добре відповідає законові зворотної пропорційності. Точно визначити міру належності неможливо, але побудова графічної моделі має говорити про те, що ця міра у більшості випадків є достатньою.
Постулат п’ятий – Для істинної графічної схеми взаємного розташування споріднених мов одного рівня на географічній карті можна знайти тільки одне місце, і це місце може бути тільки там, де проходило утворення цих мов.
Поверхня Землі є настільки різноманітною, що на ній не можна знайти подібно розчленованих територій. Тому, якщо нам вдасться розташувати побудовану графічну модель на якійсь з ділянок географічної карти, то це означає, що ніде інде ми її вже розташувати не можемо. Жодна зміна масштабів не допоможе, бо зміна масштабів не зробить подібними дві великі території на Землі. Центри можливих етноформуючих ареалів на Землі, будучи з’єднані між собою, утворюють складні геометричні фігури у формі неправильних багатокутників. Сумістити ці фігури неможливо без значної їх деформації. Наприклад, сумістити п’яти- і шестикутну зірки неможливо, якщо міняти їх пропорції і навіть в певній мірі деформувати їх форму. В принципі, при пошуках відповідної території для отримуваних багатовузлових графічних схем можна дещо коректувати положення одного-двох вузлів відповідно до географічної карти. Тим не менше в проведених дослідженнях незначна деформація отриманих схем допускалася лише як виняток, щоб уникнути довільності при відшукуванні відповідних ареалів для отримуваних схем.
Постулат шостий – Формування окремих мов із спільної прамови починається одночасно для всіх мов при заселенні нової території площею в кілька разів більшою, ніж первісна територія, і це членування стає визначальним для подальшої історії цих мов
Кількість новоутворених мов залежить від величини території і тих географічних границь, які на ній наявні. В лінгвістиці поширені погляди на існування вигаданих проміжних мов – індоіранської, балтослов’янської, кипчацько-половецької, давньоруської і т. п., ніби процес виокремлення мов проходив безперервно. Ці младограматичні погляди обумовлені ближчою спорідненістю окремих мов однієї мовної сім’ї. І хоча мови розвиваються дійсно безперервно, процес поділу їх на окремі діалекти, котрі вже далі при певних умовах перетворювалися в самостійні мови, проходив в певних часових межах, а саме – під час колонізації нових земель.
Постулат сьомий – Культурний розвиток, переселення населення в нові екологічні умови ведуть до виникнення в його мові нових слів
Словниковий склад мов збагачується двома способами – на основі власного мовного матеріалу і через запозичення. При цьому кожна мова має властивість творити нові слова за певними власини законами (Pätsch Gertrud. 1955,157). Нове слово для означення певного поняття поширюється хвилеподібно з місця утворення або запозичення в усіх напрямках по території заселення. При цьому хвиль поширення слів для того самого поняття може бути кілька, а при зустрічі ці хвилі або взаємно гасяться, або слово поширюється далі в новому, дещо зміненому значенні.
Постулат восьмий – суперпозиція етносів (нашарування одного на другой в процесі переселень) не веде до формировання нової мови.
Теорія суперпозиції сформувалася в кінці 19-го ст. і в її основі лежить припущення, засноване на історичних фактах, що при переселенні етносів якась їх частина залишається на старому місці проживання, і на нього нашаровується нове прийшле населення іншої етнічності. При цьому, як вказував Любор Нідерле в залежності від того, наскільки сильний новий шар прибульців, вони або зберігають свою народність, або втрачають її (Jaromír Korčak. 1940, 7). У разі збереження своєї народності і, відповідно, власної мови, прибульці, тим не менше, засвоюють певні елементи мови попереднього населення. Це явище отримало назву субстратного впливу. Так само прибульці засвоюють частина генофонду розчиненого серед них етносу.
Наведені тут постулати можуть виглядати самоочевидними, можливо так воно і є. Однак ми змушені були на них так довго зупинятися тому, що вони є, крім всього, і відповіддю на критичний розбір раніше опублікованої роботи.
